AI算力資源池化
AI算力資源池化人工智能(AI)做為產業變革的核心力量,不僅是技術創新,更是推動經濟發展、社會進步、行業創新的重要驅動力。作為AI市場中的重要組成, 以 GPU、 FPGA 等為主的 AI 加速器市場發展也隨之水漲船高。
由于缺乏高效經濟的 AI 算力資源池化解決方案, 導致絕大部分企業只能獨占式地使用昂貴的AI算力資源,帶來居高不下的AI算力使用成本;由于缺少對異構算力硬件支持,用戶不得不修改 AI 應用以適應不同廠商的 AI 算力硬件。 這會加劇 AI 應用開發部署復雜性、提高 AI 算力投入成本并導致供應商鎖定。
GPU資源池化技術從初期的簡單虛擬化,到資源池化,經歷了四個技術演進階段:
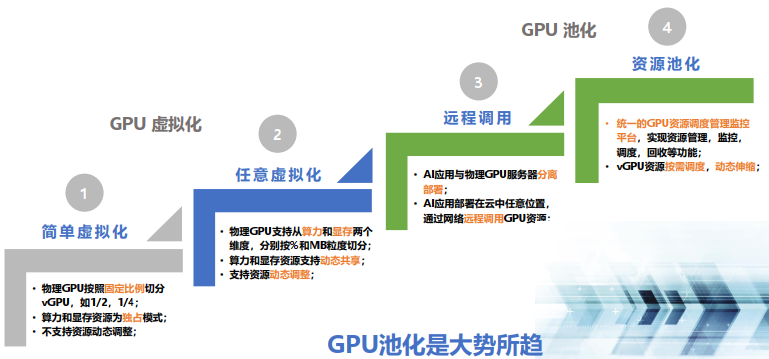
OrionX AI 算力資源池化解決方案已經實現了上述四個階段的技術功能,可以為用戶提供 GPU 資源池化的整體解決方案。
OrionX 幫助客戶構建數據中心級 AI 算力資源池, 使用戶應用無需修改就能透明地共享和使用數據中心內任何服務器之上的 AI 加速器。 OrionX 不但能夠幫助用戶提高 AI 算力資源利用率, 而且可以極大便利用戶 AI 應用的部署。
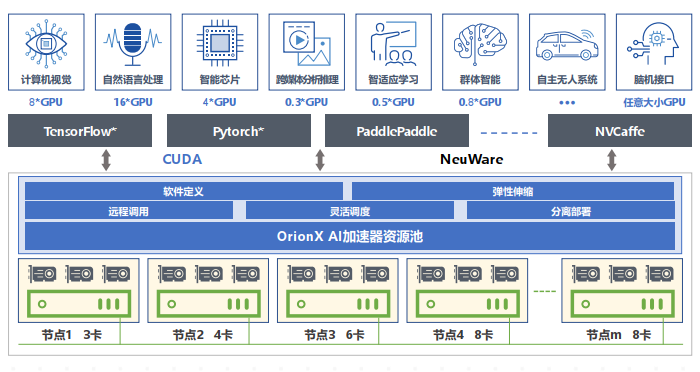
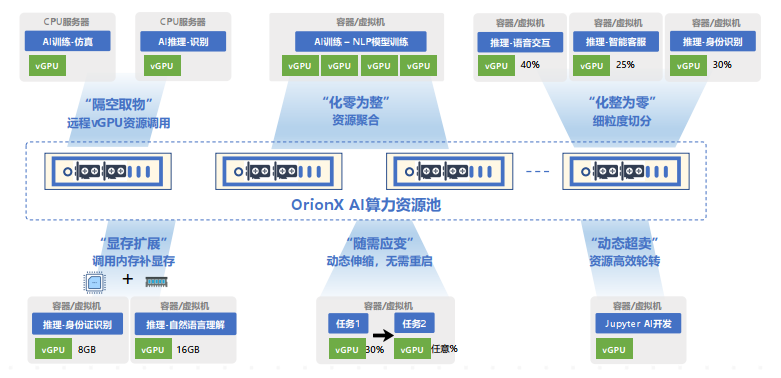
OrionX 通過軟件定義AI算力,顛覆了原有的AI應用直接調用物理GPU的架構,增加軟件層,將AI應用與物理GPU解耦合。AI應用調用邏輯的vGPU,再由OrionX將vGPU需求匹配到具體的物理GPU。OrionX 架構實現了GPU資源池化,讓用戶高效、智能、靈活地使用GPU資源,達到了降本增效的目的。
OrionX通過構建GPU資源池,讓企業內的AI用戶共享數據中心內所有服務器上的GPU算力。AI開發人員不必再關心底層資源狀況,專注于更有價值的業務層面,讓應用開發變得更加便捷。
提高利用率
支持將GPU切片為任意大小的vGPU,從而允許多AI負載并行運行,提高物理GPU利用率。
提高GPU綜合利用率多達3-10倍,1張卡相當于起到N張卡的效果,真正做到昂貴算力平民化。
高性能
相比于物理GPU,OrionX本地vGPU性能損耗幾乎為零,遠程vGPU性能損耗小于 2%。
vGPU資源隔離,并行用戶無資源互擾。
提高利用率
支持將GPU切片為任意大小的vGPU,從而允許多AI負載并行運行,提高物理GPU利用率。
提高GPU綜合利用率多達3-10倍,1張卡相當于起到N張卡的效果,真正做到昂貴算力平民化。
輕松彈性擴展
支持從單臺到整個數據中心GPU服務器納管,輕松實現GPU資源池的橫向擴展。
全分布式部署,通過RDMA(IB/RoCE)或 TCP/IP網絡連接各個節點,實現資源池彈性擴展。
靈活調度
支持AI負載與GPU資源分離部署,更加高效合理地使用GPU資源。
CPU與GPU資源解耦合,兩種服務器分開購買、按需升級、靈活調度,有助于最大化數據中心基礎設施價值。
全局管理
提供GPU資源管理調度策略。
GPU全局資源池性能監控,為運維人員提供直觀的資源利用率等信息。
對 AI 開發人員友好
一鍵解決AI開發人員面臨的訓練模型中GPU/CPU配比和多機多卡模型拆分問題,為算法工程師節省大量寶貴時間。
大模型場景如訓練場景, 對算力資源需求量大, 通常會使用一張或者多張 GPU 卡資源。
作為 AI 算力資源池平臺, OrionX 既可以支持單臺服務器上的單卡、 多卡訓練, 也可以支持跨設備的多卡訓練。
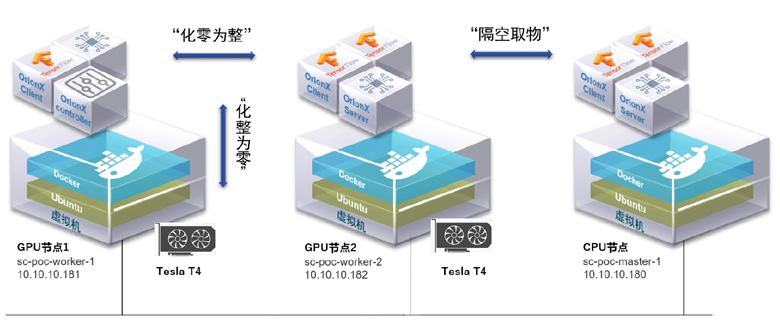
通過“化零為整”功能支持訓練
支持將多臺服務器上的 GPU 提供給一個虛擬機或者容器使用,而該虛擬機或者容器內的基于分布式訓練框架(Horovod 或 Distributed Data Parallel)的 AI 應用無需修改代碼。通過這個功能,用戶可以將多臺服務器的 GPU 資源聚合后提供給單一虛擬機或者容器使用。“化零為整”支持訓練等大模型場景,為用戶的 AI 應用提供數據中心級的海量算力。
通過“隔空取物”功能支持訓練
支持將虛擬機或者容器運行在一臺沒有物理GPU的服務器上,通過計算機網絡,透明地使用其他服務器上的GPU資源,該虛擬機或者容器內的 AI 應用無需修改代碼。通過這個功能,OrionX 幫助用戶實現了數據中心級的 GPU 資源池,實現了AI應用和GPU物理資源的解耦合,AI 應用在一個不滿足訓練條件的純CUP服務器上,也一樣能夠快速調集多個GPU卡完成訓練任務。